What is the OSIsoft PI System?
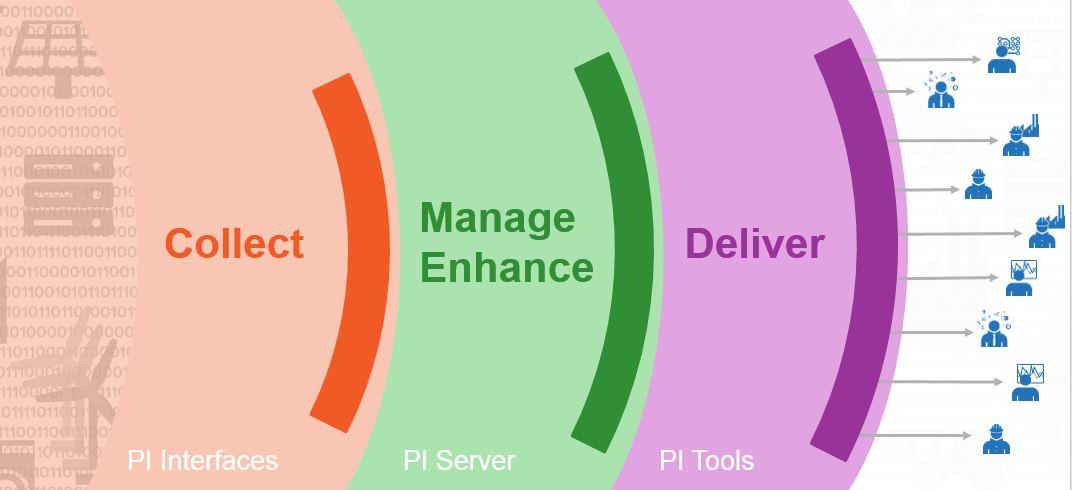
The OSIsoft PI System In the last two blog posts, I spoke about Industry 4.0 and the challenges around working with industrial […]

The OSIsoft PI System In the last two blog posts, I spoke about Industry 4.0 and the challenges around working with industrial […]

That sensor data problem A few weeks ago, I met with a number of IT consultants who had been hired to provide […]

Industry 4.0 If you work in a manufacturing related industry, it’s difficult to escape the ideas and concepts of Industry 4.0. A […]
Big data 2012 is almost over and I just realized that I have not yet posted a single entry about big data. […]
WHAT IS VISUAL ANALYTICS – BY DR JOERN KOHLHAMMER Massive sets of data are collected and stored in many areas today. As […]




